
In today’s rapidly evolving technological landscape, serverless architecture has emerged as a transformative approach to software development and deployment. This paradigm shift allows developers to build and run applications without the burden of managing servers. Serverless computing abstracts away the underlying infrastructure, enabling a focus on code and business logic. This introduction will delve into the core concepts of serverless architecture, exploring its definition, benefits, and underlying mechanisms. Understanding serverless is crucial for any developer seeking to leverage the power, scalability, and cost-effectiveness of this modern cloud-native approach.
This article provides a comprehensive overview of serverless architecture, explaining what it is and how it works. We will explore the key components of a serverless system, including Function as a Service (FaaS), Backend as a Service (BaaS), and the event-driven architecture that binds them together. We will also examine the advantages of adopting a serverless approach, such as reduced operational overhead, improved scalability, and enhanced cost efficiency. By the end of this article, you will have a solid understanding of serverless computing and its potential to revolutionize the way applications are built and deployed in the cloud.
Defining Serverless Architecture
Serverless architecture is a cloud computing execution model where the cloud provider dynamically manages the allocation of computing resources. Instead of provisioning and maintaining servers yourself, the provider takes care of all the server-side infrastructure. Applications are broken down into smaller, independent functions, and the cloud provider executes these functions on demand, scaling resources automatically based on usage.
A key characteristic of serverless computing is that you only pay for the compute time consumed when your functions are running. There are no costs associated with idle server time, significantly reducing operational costs and overhead. With serverless, developers can focus on writing code, rather than managing servers.
How It Differs from Traditional Servers
Serverless architecture diverges significantly from traditional server-based deployments. With traditional servers, you are responsible for provisioning, managing, and maintaining the server infrastructure. This includes tasks like operating system updates, security patching, and scaling resources to meet demand.
In contrast, serverless computing abstracts away the underlying infrastructure. You deploy your code as functions, and the cloud provider dynamically allocates resources to execute these functions only when triggered by events. This eliminates the need for server management, allowing developers to focus solely on their code.
The key difference lies in responsibility. Traditional servers require you to manage everything, while serverless shifts the operational burden to the cloud provider.
Use Cases and Examples
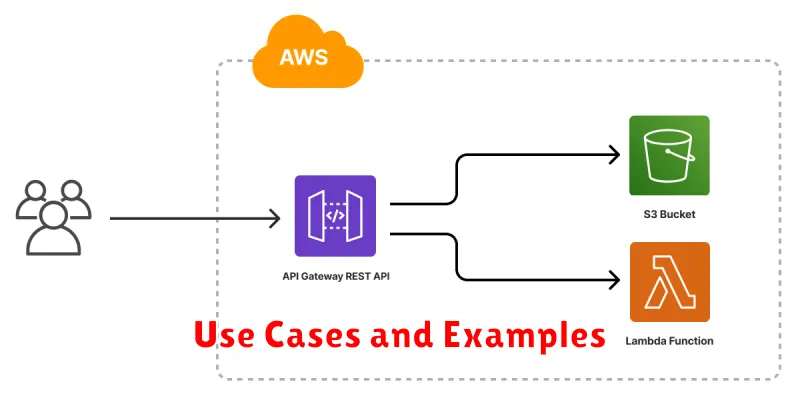
Serverless architectures excel in various scenarios. Real-time data processing is a prime example. Think of processing streaming data from IoT devices or social media feeds. Serverless functions can be triggered upon data arrival, enabling immediate analysis and action.
Backend services for web and mobile applications also benefit from serverless computing. Instead of maintaining always-on servers, developers can deploy serverless functions to handle API requests, user authentication, and database interactions. This simplifies development and reduces operational overhead.
Scheduled tasks, such as nightly backups or report generation, are another area where serverless shines. Serverless functions can be configured to execute on a predetermined schedule without requiring managing servers or cron jobs.
Benefits: Cost, Scalability, and Simplicity
Serverless architecture offers compelling advantages, primarily in cost reduction, effortless scalability, and operational simplicity. Cost efficiency stems from a pay-per-use model, eliminating expenses for idle server time. You only pay for the compute resources consumed during function execution.
Scalability is inherently managed by the cloud provider. As demand fluctuates, the platform automatically allocates resources, ensuring consistent performance without manual intervention. This eliminates the complexities of provisioning and managing servers.
Simplicity is another key benefit. Developers can focus solely on writing code without managing server infrastructure. This reduced operational overhead streamlines development cycles and accelerates time-to-market.
Limitations and Drawbacks
While serverless architecture offers numerous advantages, it also presents certain limitations and drawbacks. Vendor lock-in is a potential concern, as migrating between serverless providers can be complex. Cold starts can introduce latency when a function hasn’t been invoked recently. Debugging and monitoring can be more challenging compared to traditional server-based applications. Statelessness, while beneficial for scalability, requires careful management of application state externally.
Furthermore, serverless functions are typically subject to timeout limitations, making them unsuitable for long-running processes. Security concerns require careful consideration, especially when integrating with third-party services. Lastly, understanding the pricing models of serverless platforms is crucial to avoid unexpected costs.
Popular Serverless Providers
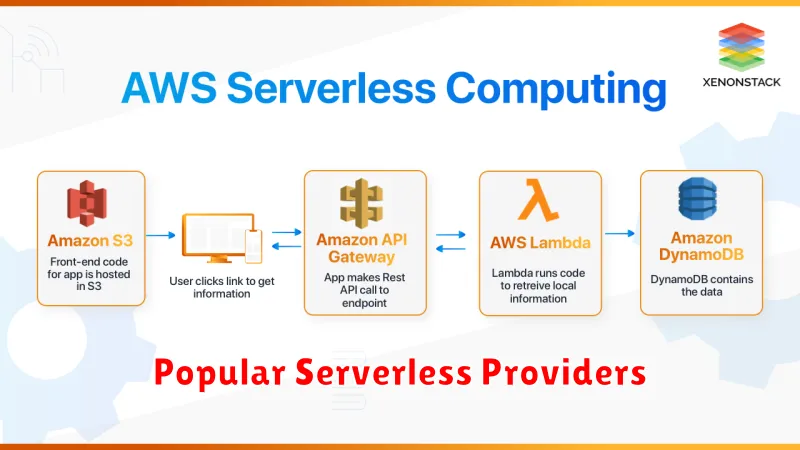
Several major cloud providers offer robust serverless computing platforms. Choosing the right provider depends on specific project needs and existing infrastructure.
Some of the most popular serverless providers include:
- AWS Lambda: A pioneer in the serverless space, AWS Lambda offers a mature platform with extensive features and integrations.
- Azure Functions: Microsoft’s serverless offering provides tight integration with other Azure services.
- Google Cloud Functions: Google’s platform is known for its scalability and event-driven architecture.
- IBM Cloud Functions: Built on Apache OpenWhisk, IBM’s platform provides open-source flexibility.
These providers each offer different pricing models, supported languages, and tooling, so it’s crucial to evaluate them based on your specific requirements.
Getting Started with Serverless
Embarking on a serverless journey involves several key steps. First, choose a serverless provider. Popular choices include AWS Lambda, Azure Functions, and Google Cloud Functions. Each offers a range of services and pricing models.
Next, define your function. This entails identifying the specific task you want to execute in a serverless manner. Consider factors like expected input and desired output.
Then, write your code using the chosen provider’s supported languages and frameworks. Be mindful of the serverless environment’s constraints, like execution time limits.
Finally, deploy and test your function. The provider’s tools typically streamline this process, enabling easy deployment and monitoring of your serverless application.
{kind=link}